如何理解 SiamRPN++?
在进入主题之前, 你需要理解目标跟踪, 孪生网络结构.
目标跟踪:
使用视频序列第一帧的图像(包括 bounding box 的位置), 来找出目标出现在后序帧位置的一种方法.
孪生网络结构:
在进入到正式理解 SiamRPN++ 之前, 为了更好的理解这篇论文, 我们需要先了解一下孪生网络的结构.
孪生网络是一种度量学习的方法, 而度量学习又被称为相似度学习.

孪生网络结构被较早地利用在人脸识别的领域 (《Learning a Similarity Metric Discriminatively, with Application to Face Verification》). 其思想是将一个训练样本(已知类别) 和一个测试样本 (未知类别) 输入到两个 CNN(这两个 CNN 往往是权值共享的)中, 从而获得两个特征向量, 然后通过计算这两个特征向量的的相似度, 相似度越高表明其越可能是同一个类别. 在上面这篇论文中, 衡量这种相似度的方法是 L1 距离.
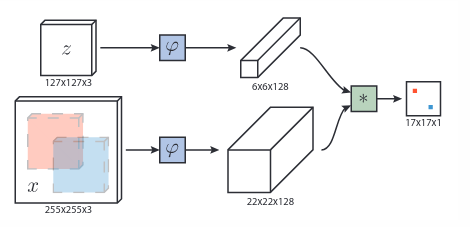
在目标领域中, 最早利用这种思想的是 SiamFC, 其网络结构如上图. 输入的 z 是第一帧 ROI(也就是在手动在第一帧选择的 bounding box),x 则是后一帧的图片. 两者分别通过两个 CNN, 得到两张特征图. 再通过一次卷积操作 (L=(22-6)/1+1=17), 获得最后形状为 17*17*1 的特征图. 在特征图上响应值越高的位置, 代表其越可能有目标存在. 其想法就类似于对上面的人脸识别孪生网络添加了一次卷积操作. 获得特征图后, 可以获得相应的损失函数. y={-1,+1} 为真实标签, v 是特征图相应位置的值. 下列第一个式子是特征图上每一个点的 loss, 第二个式子是对第一个式子作一个平均, 第三个式子就是优化目标.
However, both Siamese-FC and CFNet are lack of boundingbox regression and need to do multi-scale test which makesit Less elegant. The main drawback of these real-time track-ers is their unsatisfying accuracy and robustness comparedto state-of-the-art correlation filter approaches. 但是, Siamese-FC 和 CFNet 都没有边界框回归, 因此需要进行多尺度测试, 这使得它不太美观. 这些实时跟踪器的主要缺点是, 与最新的相关滤波器方法相比, 它们的精度和鲁棒性不令人满意.
为了解决 SiamFC 的这两个问题, 就有了 SiamRPN. 可以看到前半部分 Siamese Network 部分和 SiamFC 一模一样 (通道数有变化). 区别就在于后面的 RPN 网络部分. 特征图会通过一个卷积层进入到两个分支中, 在 Classification Branch 中的 4*4*(2k*256) 特征图等价于有 2k 个 4*4*256 形状的卷积核, 对 20*20*256 作卷积操作, 于是可以获得 17*17*2k 的特征图, Regression Branch 操作同理. 而 RPN 网络进行的是多任务的学习. 17*17*2k 做的是区分目标和背景, 其会被分为 k 个 groups, 每个 group 会有一层正例, 一层负例. 最后会用
softmax + cross-entropy loss
进行损失计算. 17*17*4k 同样会被分为 k groups, 每个 group 有四层, 分别预测 dx,dy,dw,dh. 而 k 的值即为生成的 anchors 的数目. 而关于 anchor box 的运行机制, 可以看下方第二张图(来自 SSD).
SiamRPN++
让我们正式进入主题:
- Abstract & Introduction
- However, Siamese track-ers still have an accuracy gap compared with state-of-the-art algorithms and they cannot take advantage of features from deep networks, such as ResNet-50 or deeper.(以往的 siamese 网络无法处理较深的网络)
- We observe that all these trackers have built their network upon architecture similar to AlexNet [23] and tried several times to train a Siamese tracker with more sophisticated architecture like ResNet[14] yet with no performance gain. (用的都是 AlexNet, 而在 ResNet 上效果不佳)
- Since the target may appear at anyposition in the search region, the learned feature representation for the target template should stay spatial invariant,and we further theoretically find that, among modern deep architectures, only the zero-padding variant of AlexNet satisfies this spatial invariance restriction.(只有 AlexNet 没有 padding 层才满足 spatial invariance 平移不变性)
由于 padding 层会破坏平移不变性, 而越深的网络像 ResNet-50 等具备大量 padding(这里简要解释一下, 卷积层中的参数有 stride,padding 等. 对于 stride, 只有在目标位移量 (shift) 是 stride 的整数倍时, 才满足平移不变性. 对于 padding, 同一目标在图片边缘和在图片内部的响应值不同). 因此需要解决平移不变性问题. 于是作者提出了一种打破平移不变性限制的采样策略.
By analyzing the Siamese network structure for cross-correlations, we find that its two network branches are highly imbalanced in terms of parameter number; thereforewe further propose a depth-wise separable correlation struc-ture which not only greatly reduces the parameter numberin the target template branch, but also stabilizes the trainingprocedure of the whole model. (分类分支和回归分支参数量严重不平衡)
这一点从 SiamRPN 的结构图中即可看出.
Siamese Tracking with Very Deep Networks
对于原来 siamese 网络的分析: 原先的孪生跟踪网络可以视为以下的式子:
\[ f(z,x)=\sigma(z)*\sigma(x)+b \]
而这种设计, 会导致两个限制:
The contracting part and the feature extractor used inSiamese trackers have an intrinsic restriction forstricttranslation invariance,f(z,x[4τj]) =f(z,x)[4τj],where[4τj]is the translation shift sub Windows opera-tor, which ensures the efficient training and inference.(只用某个 ROI 的区域作为 x 进行运算应该和总体进行运算后取该 ROI 的结果一致)
The contracting part has an intrinsic restriction forstructure symmetry,i.e.f(z,x′) =f(x′,z), which isappropriate for the similarity learning.(即根据相似性度量的思想, 用 z 作为卷积核和用 x 的目标位置作为卷积核效果一致)
前者也就是严格平移不变性限制, 后者就是目标相似限制.
Spatial Aware Sampling Strategy
如果特征提取网络不具有良好的平移不变性的时候(也就是采用 ResNet 或者 MobileNet 等拥有 padding 层的网络), 此时再按照 SiamFC 的训练方式, 即将所有正样本都放在中心, 那么此时会学习到位置偏见, 也就是对在中心的目标响应值最大. 测试方式为, 使用三种目标位置按照不同均匀分布的数据集进行训练, shift 值越大表示均匀分布的范围越大, 可视化结果如下图:
而这一设置均匀分布不同偏移量的策略被称为
spatial aware sampling strategy
. 作者为了确定这一策略的有效性, 又在 VOT2016 和 VOT2018 上做了测试, 发现随着 shift 范围的变大, EAO 指标 (简单来说就是视频每一帧的跟踪精度 a 的均值, 而 a 使用的是 lOU) 总体呈现上升趋势. 在这些测试中, 64 pixels 是一个良好的偏移量.
而一旦消除了深层网络对中心位置的学习偏见, 就可以根据需要利用任何结构的网络以进行视觉跟踪.
SiamRPN 对 ResNet 的 transfer
既然解决了位置偏见问题, 就可以上手使用 ResNet 网络了. 作者在这里主要是对 ResNet-50 结构进行修改. ResNet-50 结构如下:
其中 CONV BLOCK(输入输出维度不同, shortcut 用 1*1 kernel 改变维度):
ID BLOCK(输入输出尺寸一致, 便于加深网络):
The original ResNet has a large stride of 32 pixels,which is not suitable for dense Siamese network prediction.As shown in Fig.3, we reduce the effective strides at the last two block from 16 pixels and 32 pixels to 8 pixels by modifying the conv4 and conv5 block to have unit spatial stride, and also increase its receptive field by dilated convo-lutions [27]. An extra 1*1 convolution layer is appended to each of block outputs to reduce the channel to 256.
Reset 常见的 stride 值为 32, 但对于跟踪任务, 前后帧物体差距可能很小, 因此作者将最后两个 block 的 stride 改成了 8 pixels, 而且会加入一个额外的 1*1 convolution layer 将通道数变为 256. 网络会将 stage 3/4/5 的结果放入到 SiamRPN 网络中进行 Layer-wise Aggregation.
Layer-wise Aggregation 多层特征融合
In the previous works which only use shallow networkslike AlexNet, multi-level features cannot provide very dif-ferent representations. However, different layers in ResNetare much more meaningful considering that the receptivefield varies a lot. Features from earlier layers will mainlyfocus on low level information such as color, shape, are es-sential for localization, while lacking of semantic informa-tion; Features from latter layers have rich semantic informa-tion that can be beneficial during some challenge scenarioslike motion blur, huge deformation.The use of this rich hierarchical information is hypothesized to help tracking.
对于 ResNet 这种很深的网络, 不同 stage 所获得的特征也不同. 浅层 stage 获得的是 Low-level 图像特征, 而较深的 block 则偏向于获取语义信息. 因此, 使用好不同层次的特征有助于跟踪任务.
Since the output sizes of the three RPN modules have thesame spatial resolution, weighted sum is adopted directly onthe RPN output. A weighted-fusion layer combines all theoutputs.
上面已说, 网络会提取后三个 block 的结果放入 SiamRPN 网络, 而这三个 RPN 模块的输出结果形状是相同的, 所以作者这里采用的是直接加权求和各个结果:
Depthwise Cross Correlation
在 Siamese 网络中, 后面衡量相似度的是十分重要的. 如 SiamFC 的方式就是上图 (a) 的方式, 来预测一个单通道的 Response Map. 而 SiamRPN 使用的是上图 (b) 的方式, 由于引入了 anchor, 通过多个独立模板层对一个检测层的卷积操作来获得多通道独立的张量. 而这就导致了 RPN 层的参数量要远大于特征提取层. 因此引入了本文的方法 --DW-XCorr.
之所以 (b) 会产生那么多参数, 原因在于在进入 SiamRPN 的 RPN 层时, 存在一个用于提升通道数的卷积层. 而 (c) 使用的是 DW 卷积操作(下面第二张图), 也就是一个 channel 负责对一个 channel 进行卷积操作. 如下第一张图, 输入两个从 ResNet 获得的特征层(channel 数目是一致的), 先同样分别通过一个卷积层(由于需要学的任务不同, 所以卷积层参数不共享), 再分别进行 DW 卷积操作, 然后两分支再分别通过一层不同的卷积层改变通道数以获得想要的分类和回归结果. 这样一来, 就可以减少计算量, 且使得两个分支更加平衡.
而通过这种方式, 在不同的通道对其相应的类会有不错的响应, 而其他类则会有所抑制, 也就是这种方式能够记住一些不同类别的语义信息. 而 (2) 的 up-channel 方式却没有这种性质.
实验结果
在成功识别率, SiamRPN++ 位于第一位, 在精度 (识别框中心位置) 方面, 位于第三.
EAO 值位于第一, 远超第二名.
对于比较长的视频序列, SiamRPN++ 也位居第一的位置.
来源: https://www.cnblogs.com/IaCorse/p/12520770.html