读懂 Java 字节码 (2)

java-logo.jpg
要查看 class 的字节码有很多方式, 这里我选择自己比较喜欢 vscode 提供插件来查看, 下载下图的插件安装后就可以在 vscode 中查看字节码文件.
hexdump.JPG
表示 coffee baby 这是模数, 也是校验这个文件是 JVM 认可的字节码文件. 如果要是我开发的就修改为 ZI EA 呵呵
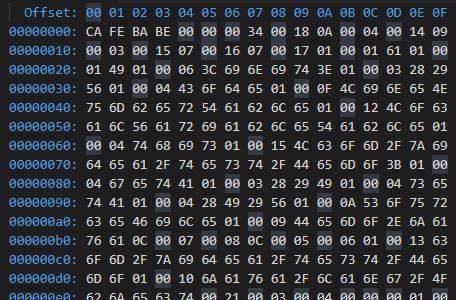
byte_code.JPG
魔数
CA FE BA BE
前 u4 前四个字节是魔数, 表示 coffee baby 这是模数, 也是校验这个文件是 JVM 认可的字节码文件. 如果要是我开发的就修改为 ZI EA 呵呵
版本信息
00 00 00 34
00 00 前两位代表小版本号
00 34 表示 52 是 java 版本号 52 对应 java 1.8
- java version "1.8.0_171"
- Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
- Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
常量池数量
00 18
24(1 * 16 + 8 = 24) 代表有 23 个常量, 为什么是 23 常量而不是 24 常量, 因为 0 作为 JVM 保留常量, 常量是从 1 开始的, 所以需要减去 1 为 24
0A
常量池是以数据表的结构来保存常量信息, 这里表是按既定的顺序来组织一类数据. 每一个常量根据类型不同而有不同的长度. 那么也就是说常量池的长度是可变的. JVM 如何知道读取到哪一位置就结束了常量池呢. 首先根据 18(24) 进行一条一条地读取常量, 每一个常量根据类型可以计算出其长度. 这样 JVM 就很容易就可以计算出常量池结束位置.
在开始之前先介绍一下在字节码有关基本类型和引用类型表示, 在字节码文件中要尽可能节省空间, 所以使用大写字母来表示类型, 而且字节码是给机器阅读的.
基本类型 I(int)
constant_table.PNG
这里列出 12 中基本常量, 在 JDK 1.7 之后又新增了三种常量, 这里不作为重点所以没有罗列出. 我们先看一下表, 根据结构, 常量名称 CONSTANT_utf8_info ,tag 表示常量类型占一个字节, 这里的 U1 表示一个字节, 然后是长度为 U2 两个字节, 先不说了我们通过表来在字节码中读取几个常量就能明白了.
我们使用以上表对应去查找就可以读懂常量池的字节码代表含义了.
接着表示常量数量字节码向下读取
0A
表示 11 对应表中的 CONSTANT_InterfaceMethodref_info 好, 找到类型我们继续向下看, 第一个两个字节表示引用指向该字段或名称常量项的索引, 继续向下两个字节为
00 04
我们可以现在 javap 编译后可读性较高的文件看一下 4 是什么东西
#4 = Class #23 // java/lang/Object
04 表示指向 4 , 其实就是定义构造函数的 <init>
接下来是两个字节是
00 14
14 转为 20 (16 + 4) 这里指向一个 20 的在可读 class 文件中内容为两个引用 7 和 8 , 让后将 7 和 8 内容获取进行简单拼接就是 <init>()V
- #7 = Utf8 <init>
- #8 = Utf8 ()V
- #9 = Utf8 Code
- #20 = NameAndType #7:#8 // "<init>":()V
使用 javap 命令将字节码文件呈现可读文件中对应下面字节码
0A 00 04 00 14
的文本为
#1 = Methodref #4.#20 // java/lang/Object."<init>":()V
1 代表第一行, 0A 代表 Methodref 常量的类型,#4 #20 表示两个引用, 通过获取两个引用组成字符串为 java/lang/Object."<init>":()V.
java_bean.jpg
来源: http://www.jianshu.com/p/4695432a9724