Java 虚拟机与垃圾回收算法
接下来会有几篇文章专门讲解 Android 系统中的虚拟机, 本文是序篇, 主要是为了后面讲解 Dalvik 和 ART 虚拟机做一些铺垫. 在本中我们将对 Java 虚拟机以及虚拟机中的垃圾回收算法做一定的介绍.
Java 语言
Java 是一种计算机编程语言, 拥有跨平台, 面向对象, 泛型编程的特性, 广泛应用于企业级 web 应用开发和移动应用开发.
任职于 Sun 公司的 James Gosling 等人于 1990 年代初开发 Java 语言的雏形, 最初被命名为 Oak, 目标设置在家用电器等小型系统的程序语言, 应用在电视机, 电话, 闹钟, 烤面包机等家用电器的控制和通信. 由于这些智能化家电的市场需求没有预期的高, Sun 公司放弃了该项计划. 随着 1990 年代互联网的发展, Sun 公司看见 Oak 在互联网上应用的前景, 于是改造了 Oak, 于 1995 年 5 月以 Java 的名称正式发布. Java 伴随着互联网的迅猛发展而发展, 逐渐成为重要的网络编程语言.
Java 编程语言的风格十分接近 C++ 语言. 继承了 C++ 语言面向对象技术的核心, Java 舍弃了 C++ 语言中容易引起错误的指针, 改以引用替换, 同时移除原 C++ 与原来运算符重载, 也移除多重继承特性, 改用接口替换, 增加垃圾回收器功能. 在 Java SE 1.5 版本中引入了泛型编程, 类型安全的枚举, 不定长参数和自动装 / 拆箱特性. Sun 公司对 Java 语言的解释是:"Java 编程语言是个简单, 面向对象, 分布式, 解释性, 健壮, 安全与系统无关, 可移植, 高性能, 多线程和动态的语言".
Java 不同于一般的编译语言或直译语言. 它首先将源代码编译成字节码, 然后依赖各种不同平台上的虚拟机来解释执行字节码, 从而实现了 "一次编写, 到处运行" 的跨平台特性. 在早期 JVM 中, 这在一定程度上降低了 Java 程序的运行效率. 但在 J2SE1.4.2 发布后, Java 的运行速度有了大幅提升.
与传统类型不同, Sun 公司在推出 Java 时就将其作为开放的技术. 全球数以万计的 Java 开发公司被要求所设计的 Java 软件必须相互兼容."Java 语言靠群体的力量而非公司的力量" 是 Sun 公司的口号之一, 并获得了广大软件开发商的认同. 这与微软公司所倡导的注重精英和封闭式的模式完全不同.
2009 年 Sun 公司被甲骨文公司并购, Java 也随之成为甲骨文公司的产品.
Java 虚拟机
Java 虚拟机 (Java Virtual Machine, 缩写为 JVM) 是一种能够运行 Java bytecode 的虚拟机, 以堆栈结构来进行操作. JVM 有三个概念: 规范, 实现和实例. 规范是一个正式描述 JVM 实现所需要的文档, 具有单个规范确保所有实现是可互操作的. JVM 实现是一种满足 JVM 规范要求的计算机程序. JVM 的实例是在执行编译成 Java 字节码的计算机程序的过程中运行的实现.
Java 虚拟机有自己完善的硬体架构, 如处理器, 堆栈, 寄存器等, 还具有相应的指令系统. JVM 屏蔽了与具体操作系统平台相关的信息, 使得 Java 程序只需生成在 Java 虚拟机上运行的目标代码(字节码), 就可以在多种平台上不加修改地运行.
Java 虚拟机并不知道 Java 编程语言, 只知道一个特定的二进制格式: class 文件格式. class 文件包含了 Java 虚拟机的指令 (或字节码) 和符号表, 以及其他辅助信息.
Java 虚拟机实现架构
下图是 HotSpot JVM 的实现架构:

HotSpot 是我们最为熟悉的 Java 虚拟机实现. 因为这是 Sun JDK 以及 OpenJDK 中所带的虚拟机.
从这幅图中我们看到, HotSpot 虚拟机的实现包含如下几个组成部分:
类加载器子系统: 负责加载和验证 class 文件
运行时数据区: JVM 运行时的内存资源, 运行时数据区可以分为以下几个部分:
方法区: 存储了类代码和方法代码
堆: 通过 new 创建的对象都在堆中分配
Java 线程: 一个 Java 程序可能创建了多个线程, 每个线程都会有自己的栈
程序计数寄存器: 存储了执行指令的内存地址
本地方法栈: 本地方法 (例如: C/C++ 语言) 执行的区域
执行引擎: 执行引擎是真正运行 Java 代码的模块, 它包括了:
JIT(Just-In-Time)编译器: 负责将字节码转换为机器码
垃圾收集器: 负责回收不再使用的对象
本地方法接口: 运行虚拟机与本地方法互相调用
本地方法库: 包含了本地库的信息
需要注意的是, HotSpot 并非唯一的 JVM 实现, 目前市面上还有很多其他公司和组织实现的 Java 虚拟机, 例如 BEA JRockit,IBM J9 等.
类加载器(Class loader)
JVM 字节码以 class 文件为组织单位. 类加载器实现必须能够识别和加载符合 Java class 文件格式的任何内容. 任何实现都可以自由地识别除类文件之外的其他二进制形式, 但它必须识别 class 文件.
类加载器以这个严格的顺序执行三个基本活动:
加载: 查找和导入类的二进制数据
链接: 执行验证, 准备和 (可选) 解析
验证: 确保导入类型的正确性
准备: 为类变量分配内存并将内存初始化为默认值
解析: 将符号引用从类型转换为直接引用.
初始化: 调用将代码初始化为正确的初始值的 Java 代码.
一般来说, 有两种类型的类加载器: 引导类加载器和用户自定义类加载器. 每个 Java 虚拟机实现必须一个引导类加载器, 用来加载受信任的类. 但 Java 虚拟机规范没有指定类加载器应该如何定位类.
垃圾回收
Java 与 C++ 之间有一堵由内存动态分配和垃圾收集技术所围成的 "高墙", 墙外面的人想进去, 墙里面的人却想出来. - 周志明, 《深入理解 Java 虚拟机: JVM 高级特性与最佳实践(第 2 版)》
Java 语言与 C/C++ 语言最大的区别在于内存的管理. 在 C/C++ 中, 内存的申请和释放都必须由程序员手动管理, 而在 Java 语言中, 程序员只需要关注对象的创建即可. 虚拟机中包含了垃圾回收器, 专门负责内存的回收.
垃圾回收是一种自动的内存管理机制. 当内存中的对象不再需要时, 就应该予以释放, 以让出存储空间, 这种内存资源管理, 称为垃圾回收(garbage collection). 垃圾回收器可以减轻程序员的负担, 也减少程序员犯错的机会. 垃圾回收最早起源于 LISP 语言. 目前许多语言如 Smalltalk,C# 和 D 语言都支持垃圾回收.
垃圾回收包括两个问题需要解决:
收集: 确定哪些对象已经不会再被使用到
回收: 释放这些对象以回收内存
收集的过程就是确定堆中的对象有哪些已经不再使用. 如下图所示, 蓝色部分的对象是仍然存活的对象, 而黄色部分的对象已经不再被使用, 可以被回收:
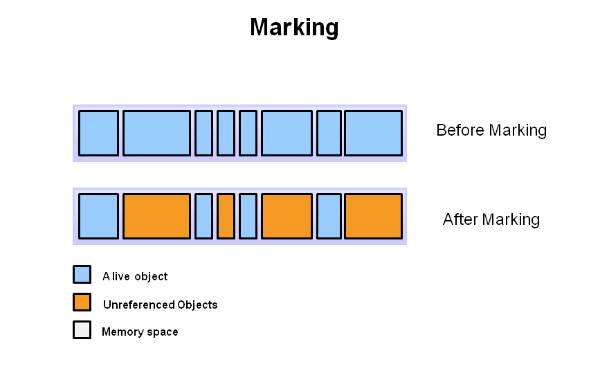
而回收就是将这些对象销毁掉以回收内存, 但直接的释放会造成堆中留下很多大小不一的碎片, 如下图所示:
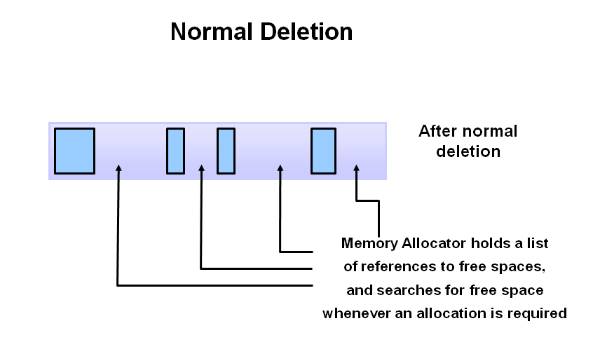
因此好的回收算法还要对遗留下的碎片进行处理, 下文会讲解具体做法.
收集算法
垃圾收集主要有下面两种算法:
引用计数: 为每个对象附上一个引用计数的状态记录, 每当对象被另外一个对象引用时, 引用计数加 1, 每当引用减少时, 引用计数减 1. 当对象的引用计数为 0 时, 便认为该对象不再被使用. 但这种算法有一个很明显的问题, 就是需要解决两个对象互相引用对方的问题.
对象追踪: 对象追踪算法是以根对象为起点, 追踪所有被这些对象所引用的对象, 并顺着这些被引用的对象继续往下追踪, 在追踪的过程中, 对所有被追踪到的对象打上标记. 而剩下的那些没有被打过标记的对象便可以认为是没有被使用的, 因此这些对象可以被释放掉.
虚拟机中垃圾回收的根对象通常是下面这四种类型的对象:
栈中的 local 变量, 即方法中的局部变量
活动的线程(包括主线程和应用程序创建的子线程)
static 变量
JNI 中的引用
回收算法
回收算法包括下面几种:
标记 - 清除: 先暂停整个程序的全部运行线程, 让回收线程以单线程进行扫描标记, 并进行直接清除回收, 然后回收完成, 再恢复运行线程. 前面我们已经说了, 这种算法会产生大量零碎的空闲空间碎片, 导致大容量对象不容易获得连续的内存空间, 而造成空间浪费.
标记 - 压缩: 和 "标记 - 清除" 相似, 不同的是, 该算法在回收期间会同时将保留下来的对象移动聚集到连续的内存空间, 从而避免内存空间碎片. 以上面的图为例, 该算法会将蓝色区域的对象全部移动到一起, 使得中间不出现黄色的碎片区域. 但对象的移动是需要时间成本的.
复制: 该算法会将所拥有的内存空间分成两个部分. 程序运行所需的存储对象先存储在其中一个分区中(例如: 定义为 "分区 0"). 算法执行过程中暂停整个程序的全部运行线程后, 进行标记, 然后将保留下来的对象移动聚集到另一个分区(例如: 定义为 "分区 1"), 这样便完成了回收. 在下一次回收时, 两个分区的角色对调. 很显然, 这种算法虽然避免了内存碎片, 但对内存空间的使用是比较浪费的, 因为始终只能有一半的空间用来使用.
增量回收: 该算法将所拥有的内存空间分成若干分区. 程序运行所需的存储对象会分布在这些分区中, 每次只对其中一个分区进行回收操作, 从而避免程序全部运行线程暂停来进行回收, 允许部分线程在不影响回收行为而保持运行, 并且降低回收时间, 增加程序的响应速度.
分代:"复制" 算法在极端的情况下, 会出现明显的问题, 例如: 某些很大的对象, 它们的生命周期又很长, 那么这些对象便会在分区之间来回移动, 这显示是很耗时的. 而基于 "分代" 的算法是这样运作的: 将所拥有的内存空间分成若干个分区, 并标记为 "年轻代" 空间和 "老年代" 空间. 程序运行所需的存储对象会先存放在年轻代分区, 年轻代分区会较为频繁的进行较为激进垃圾回收行为, 每次回收完成存活下来的对象的寿命计数器加一. 当年轻代分区存储对象的寿命计数器达到一定阈值或存储对象的占用空间超过一定阈值时, 则被移动到老年代空间, 老年代空间会较少的运行垃圾回收行为. 一般情况下, 还有永久代的空间, 用于涉及程序整个运行生命周期的对象存储, 例如运行代码, 数据常量等, 该空间通常不进行垃圾回收的操作. 通过分代, 存活在局限域, 小容量, 寿命短的存储对象会被快速回收; 存活在全局域, 大容量, 寿命长的存储对象就较少被回收行为处理干扰.
后面的内容中我们将看到, Davlik 虚拟机的垃圾回收主要使用了 "标记 - 清除" 算法. 而 ART 虚拟机中垃圾回收机制的改进, 其实是结合了多种垃圾回收算法(其实不仅仅是 ART 虚拟机, 大部分的现代虚拟机都会同时包含多个垃圾回收器), 而这些算法, 基本就是上面提到的这些.
最后给大家分享一份非常系统和全面的 Android 进阶技术大纲及进阶资料, 及面试题集
想学习更多 Android 知识, 请加入 Android 技术开发交流 7520 16839
进群与大牛们一起讨论, 还可获取 Android 高级架构资料, 源码, 笔记, 视频
包括 高级 UI,Gradle,RxJava, 小程序, Hybrid, 移动架构, React Native, 性能优化等全面的 Android 高级实践技术讲解性能优化架构思维导图, 和 BATJ 面试题及答案!
群里免费分享给有需要的朋友, 希望能够帮助一些在这个行业发展迷茫的, 或者想系统深入提升以及困于瓶颈的
朋友, 在网上博客论坛等地方少花些时间找资料, 把有限的时间, 真正花在学习上, 所以我在这免费分享一些架构资料及给大家. 希望在这些资料中都有你需要的内容.
来源: http://www.jianshu.com/p/39e9e720304b