python 中 open 函数的使用
一 open() 的函数原型
open(file, mode=r, buffering=-1, encoding=None, errors=None, newline=None, closefd=True)
从官方文档中我们可以看到 open 函数有很多的参数, 我们常用的是 file,mode 和 encoding, 对于其它的几个参数, 平时不常用, 也简单介绍一下
buffering 的可取值有 0,1, >1 三个, 0 代表 buffer 关闭 (只适用于二进制模式),1 代表 line buffer(只适用于文本模式),>1 表示初始化的 buffer 大小;
encoding 表示的是返回的数据采用何种编码, 一般采用 utf8 或者 gbk;
errors 的取值一般有 strict,ignore, 当取 strict 的时候, 字符编码出现问题的时候, 会报错, 当取 ignore 的时候, 编码出现问题, 程序会忽略而过, 继续执行下面的程序
newline 可以取的值有 None, \n, \r, , \r\n , 用于区分换行符, 但是这个参数只对文本模式有效;
closefd 的取值, 是与传入的文件参数有关, 默认情况下为 True, 传入的 file 参数为文件的文件名, 取值为 False 的时候, file 只能是文件描述符, 什么是文件描述符, 就是一个非负整数, 在 Unix 内核的系统中, 打开一个文件, 便会返回一个文件描述符
二 file() 与 open()
两者都能够打开文件, 对文件进行操作, 也具有相似的用法和参数, 但是, 在我看来, 这两种文件打开方式有本质的区别, file 为文件类, 用 file() 来打开文件, 相当于这是在构造文件类, 而用 open() 打开文件, 是用 python 的内建函数来操作
三参数 Mode 的基本取值

rwa 为打开文件的基本模式, 对应着只读只写追加模式;
bt+U 这四个字符, 与以上的文件打开模式组合使用, 二进制模式, 文本模式, 读写模式通用换行符, 根据实际情况组合使用
四 常见的 mode 取值组合
1r 或 rt 默认模式, 文本模式读
2rb 二进制文件
3w 或 wt 文本模式写, 打开前文件存储被清空
4wb 二进制写, 文件存储同样被清空
5a 追加模式, 只能写在文件末尾
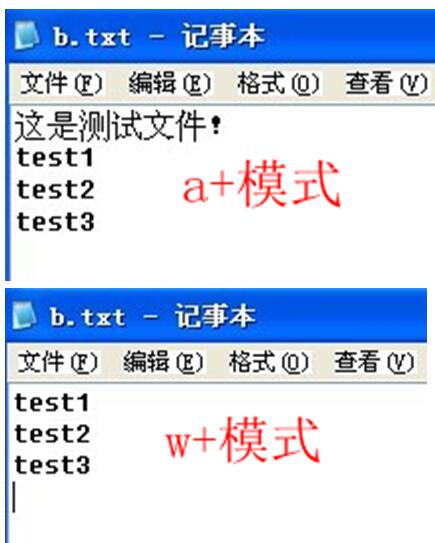
6a+ 可读写模式, 写只能写在文件末尾
7w+ 可读写, 与 a + 的区别是要清空文件内容
8r+ 可读写, 与 a + 的区别是可以写到文件任何位置
五几个模式的区别
为了测试不同模式的区别, 我们用一小段代码来测试写入文件中的直观不同
- test = [ "test1\n", "test2\n", "test3\n" ]
- f = open( "b.txt", "a+")
- try:
- for s in test:
- f.write( s )
- finally:
- f.close()
(1)a + 与 w + 模式的区别
(2)a + 与 r + 模式
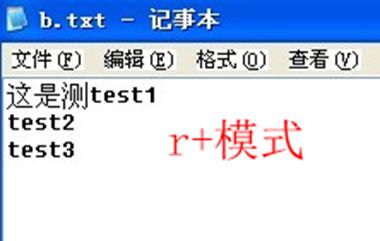
在写入文件前, 我们在上面那段代码中加上一句 seek(6), 用来定位写入文件写入位置
注意: r + 模式打开文件时, 此文件必须存在, 否则就会报错, r 模式也如此
六换行符带来的烦恼
当你用二进制模式将带有换行符的字符串写入 txt 文件时, 数据存储是正确的, 但是当用 windows 平台的记事本程序打开时, 你看到的换行符确实一个个的小黑块, 但是, 用文本模式, 就不存在这样的问题
在这里, 涉及到了不同平台由于编码的问题, 而对换行符有不同的识别 unix 或者 linux 系统识别 \ n 为换行符的标识, 但是 windows 平台的编码, 对 \ n 不予理睬
但是 python 自身带有转化功能, 用文本模式的时候, 你不会看到由于平台不同而造成的换行效果不同, 但是, 二进制模式的时候, python 便不会再去转化, 是什么, 就写进去什么, 此时的换行符, 再用文本模式打开, windows 下就不识别 \ n 换行符了
来源: http://www.bubuko.com/infodetail-2486579.html