java多线程之一/Java内存模型(JMM)
在讲解之前,先区别两个概念:java内存模型与JVM内存模型。
- java内存模型:JMM(Java Memory Model),JMM的目的是为了解决Java多线程对共享数据的读写一致性问题,通过
语义定义了Java程序对数据的访问规则,修正之前由于读写冲突导致的Cache数据不一致的问题。这是一种逻辑抽象,并没有对应内存实体。它规范了(本文将重点讲解)- Happens-Before
- JVM内存模型:是指JVM运行过程中数据区域,参见链接,此为实实在在存在着的内存区域。
上面已讲,JMM只是逻辑抽象,没有与其对应的内存运行区域,故不要将两者混着学,否则,你会疯。
Java并发编程遇到的问题
我们在多线程编程中解决的两个最常见的问题:
- 多线程之间如何操作同一变量;
- 多线程中如何处理同步问题。
java是跨平台语言,不同处理器架中都有自己高速缓存,并处理与主内存的通信协调。不同的处理器架构也都提供了自己的缓存一致性。java为了实现跨平台的语言特性,在
中提出了JMM规范,用于解决上述复杂的多平台问题。 JMM决定了一个线程对共享便利那个的写入何时对另一个线程可见。JMM定义了一个抽象关系:
- [JSR-133]
线程之间的
存储在
- 共享变量
中,每个线程都有一个私有的
- 主内存
,
- 工作内存
中存储了共享变量的副本(类似于CPU中高速缓存与内存的关系,其实
- 工作内存
包含了高速缓存的概念)。
- 工作内存
是一个抽象概念,并不存在于真实内存中。
- 工作内存
如图所示:
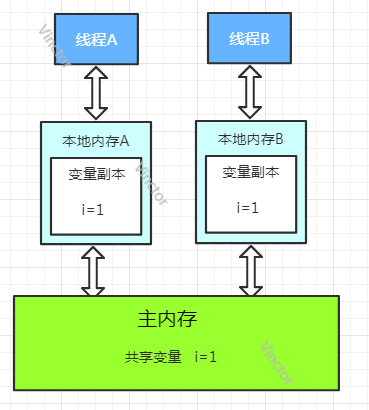
image.png
- public class Test {
- private int i = 1;
- //线程A修改
- public void setVar() {
- i = 2;
- }
- //线程B获取
- public int getVar() {
- return i;
- }
- }
线程A修改变量并对线程B可见需要通过以下步骤:
1 .(setVar) 线程A修改本地内存A中的变量副本(A),
并刷新到主内存中(B);
2 . (getVar)线程B从主内存拿取变量值,更新本地内存B中的值
可见性与原子性
上述两个步骤,如果线程A对变量的修改能够正确的显示在线程B中,(即:一个线程修改的状态对另一个线程是可见的),称为
。
- 可见性
如果要保证上述代码能够正确运行,则需要保证步骤1的操作不可被拆分,需要按照:
的顺序执行,如果出现了
- 线程A(A->B)->线程B
这样的顺序执行,则会出现获取数据错误的问题。我们需要保证
- 线程A(A)->线程B->线程A(B)
是原子操作,这称为
- setVar
。
- 原子性
指令重排序
无论是处理器还是JVM,唯一的宗旨就是在保证处理结果正确的前提下,尽最大可能的提高程序运行效率。为了提高运行效率,编译器,处理器执行期间,处理器高速缓存在回写主内存时都对运算指令进行了优化重排序。如下代码(摘自java并发编程艺术):
- class ReorderExample {
- int a = 0;
- boolean flag = false;
- //线程A
- public void writer() {
- a = 1; // 1
- flag = true; // 2
- }
- //线程B
- public void reader() {
- if (flag) { // 3
- int i = a * a; // 4
- }
- }
- }
flag变量是个标记,用来标识变量a是否已被写入。这里假设有两个线程A和B,A首先执行writer()方法,随后B线程接着执行reader()方法。线程B在执行操作4时,线程A拿到的a的值不一定是最新的。看下图:

image.png
程序在运行过成中,操作1和操作2可能会做了指令重排序,1和2颠倒执行,这在单线程中没有任何问题,但是在多线程中就会出现错误。
happens-before语义
Java内存模型使用了各种操作来定义的,包括对变量的读写,监视器的获取释放等,JMM中使用了
语义阐述了操作之间的内存可见性。如果想要保证执行操作B的线程看到操作A的结构(无论AB是否在同一线程),那么A,B必须满足
- happens-before
关系。如果两个操作之间缺乏
- happens-before
关系,那么JVM可以对他们进行任意的重排序。
- happens-before
happens-before规则包括:
- 程序顺序规则。一个线程中,如果操作A在B之前,那么线程中A操作将在B操作之前执行。
- 监视器锁规则。在监视器锁上的解锁操作必须在同一个监视器锁上的佳作之前执行。
- volatile规则。对volatile变量的写入操作必须在对改变的读操作之前进行。
- 线程启动规则。在线程上对Thread.start()的调用必须在对线程执行任何操作之前执行。
- 线程结束规则。线程中的任何操作都必须在其他线程检测到该线程已经结束之前执行。
- 终结器规则。对象的构造函数必须在启动该对象的终结器之前执行完成。
- 传递性。如果操作A在B之前执行,并且操作B在C之前执行,那么操作A在C之前执行。
我们在写代码过程中,当一个变量被多个线程读取并且被至少一个线程写入的时候,如果在读操作与写操作之前没有实现
排序,则就会产生数据竞争问题,产生错误的结果。
- happens-before
来源: https://juejin.im/entry/5a0bef545188253293141473